Linear SVM
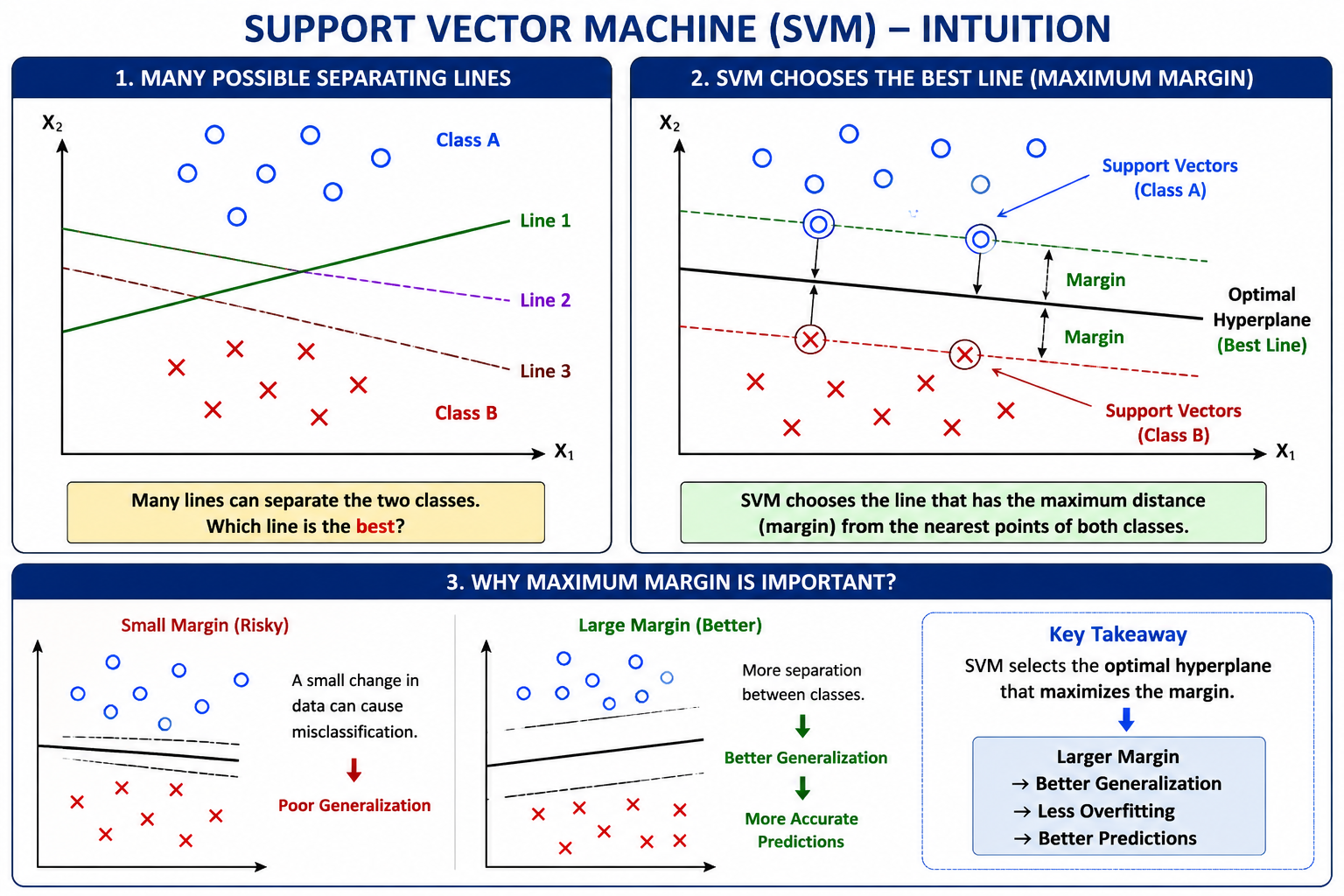
Support Vector Machine, commonly called SVM, is a supervised machine learning algorithm mainly used for classification problems.
The main goal of SVM is:
To find the best decision boundary that separates different classes.
In classification, many boundaries may separate the data correctly. But SVM chooses the boundary that gives the maximum margin between classes.
So, SVM is also called a:
Maximum Margin Classifier
Simple Intuition
Suppose we have two classes:
Class A: ○ ○ ○ ○
Class B: × × × ×
Many lines can separate them.
But SVM asks:
Which line separates the classes most safely?
The safest line is the one that keeps maximum distance from both classes.
That distance is called the margin.
Types of SVM
SVM can be mainly divided into two types:
1. Linear SVM
Linear SVM is used when data can be separated using a straight line.
Example:
○ ○ ○ ○ | × × × ×
Here, a straight line can separate the two classes.
So we use Linear SVM.
2. Non-Linear SVM
Non-Linear SVM is used when data cannot be separated using a straight line.
Example:
○ ○ × ○
× ○ × ×
○ × ○ ×
Here, a simple straight line cannot separate the classes properly.
So we use Non-Linear SVM with kernel functions.
Linear Support Vector Machine
Linear SVM is a classification algorithm that separates classes using a straight decision boundary.
In 2D data, the decision boundary is a line.
In 3D data, the decision boundary is a plane.
In higher dimensions, it is called a hyperplane.
Main Concept of Linear SVM
The main concept of Linear SVM is:
Find a straight hyperplane that separates classes with the largest possible margin.
It does not just find any separating line.
It finds the best separating line.
What is a Hyperplane?
A hyperplane is the decision boundary that separates classes.
For 2D:
Hyperplane = Line
For 3D:
Hyperplane = Plane
For higher dimensions:
Hyperplane = Separating surface
Mathematically:
wᵀx + b = 0
Where:
w = weight vector
x = input feature vector
b = bias
What is Margin?
Margin is the distance between the hyperplane and the nearest data points from both classes.
SVM tries to maximize this margin.
Large margin means:
Better separation
Better generalization
Less overfitting
What are Support Vectors?
Support vectors are the closest data points to the hyperplane.
These points are very important because they decide the position of the hyperplane.
If support vectors change, the hyperplane changes.
But points far away from the hyperplane usually do not affect the boundary much.
That is why the algorithm is called:
Support Vector Machine
because these important vectors support the final decision boundary.
How Linear SVM Works
Step 1: Take Labeled Data
Example:
| X1 | X2 | Class |
|---|---|---|
| 1 | 1 | -1 |
| 2 | 1 | -1 |
| 4 | 3 | +1 |
| 5 | 4 | +1 |
Here:
-1 = Class AStep 2: Search for Separating Lines
+1 = Class B
Many lines can separate the two classes.
But Linear SVM does not choose any random line.
It checks which line gives the maximum margin.
Step 3: Find the Closest PointsThe closest points from each class are selected.
These closest points are called support vectors.
Example:
(2,1) from Class -1
(4,3) from Class +1
These points mainly decide the decision boundary.
Step 4: Create the Maximum Margin BoundaryThe boundary is placed between the support vectors in such a way that the distance from both classes is maximum.
The final boundary is called the optimal hyperplane.
Step 5: Classify New DataOnce the hyperplane is created, new data is classified based on which side of the hyperplane it falls.
For example:
If point is on one side → Class +1Mathematical View of Linear SVM
If point is on other side → Class -1
The hyperplane equation is:
wᵀx + b = 0
Prediction function:
f(x) = wᵀx + b
Decision rule:
If f(x) > 0 → Class +1
If f(x) < 0 → Class -1
For correct classification:
yᵢ(wᵀxᵢ + b) ≥ 1
Where:
yᵢ = actual class labelMargin Formula
xᵢ = input data point
The margin width is:
2 / ||w||
Here:
||w|| = length of weight vector
To maximize margin, SVM tries to minimize:
||w||
So the optimization goal is:
Minimize ||w|| while correctly classifying all data points.Soft Margin Linear SVM
In real-world datasets, perfect separation is not always possible.
Sometimes data points overlap.
So Linear SVM allows some mistakes using Soft Margin SVM.
Soft Margin SVM uses a parameter called C.
Role of C ParameterThe parameter C controls the balance between margin size and classification errors.
Small C
Small C allows some misclassification.
Result:
Wider margin
More tolerance
Better generalization
Large C
Large C tries to classify every training point correctly.
Result:
Narrow margin
Less tolerance
Possible overfitting
Linear SVM Example
Assume final hyperplane is:
x1 + x2 - 5 = 0
For point (6,2):
f(x) = 6 + 2 - 5
= 3
Since value is positive:
Prediction = Class +1
For point (1,2):
f(x) = 1 + 2 - 5
= -2
Since value is negative:
Prediction = Class -1
Python Implementation
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X = [[1,1], [2,1], [4,3], [5,4]]
y = [-1, -1, 1, 1]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
model = SVC(kernel="linear", C=1.0)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("Predictions:", y_pred)
print("Accuracy:", accuracy_score(y_test, y_pred))
Advantages of Linear SVM
-
Works well for linearly separable data
-
Effective in high-dimensional datasets
-
Good for text classification
-
Less overfitting due to margin maximization
-
Strong mathematical foundation
Limitations of Linear SVM
-
Not suitable for non-linear data
-
Sensitive to outliers
-
Choosing the right C value is important
-
Training can be slow for very large datasets
-
Does not directly provide probabilities
Important Points
-
SVM stands for Support Vector Machine.
-
SVM is a maximum margin classifier.
-
Linear SVM separates classes using a straight hyperplane.
-
The closest points to the hyperplane are called support vectors.
-
Support vectors decide the final decision boundary.
-
Margin is the distance between the hyperplane and support vectors.
-
Linear SVM tries to maximize margin.
-
The prediction depends on the sign of wᵀx + b.
-
Soft Margin SVM allows some classification errors.
-
The parameter C controls margin size and misclassification.
Keywords
Support Vector Machine, Linear SVM, Maximum Margin Classifier, Hyperplane, Support Vectors, Margin Maximization, Soft Margin SVM, C Parameter, Decision Boundary, SVM Classification



